本文翻译自:I want my AOP
关注点表示人们的一种特殊的意愿、理念或是某个感兴趣的领域。从技术角度来讲:软件系统包括若干核心的、系统级别的关注点。比方说:信用卡处理系统的核心关注点是处理交易,同时系统级别的关注点或许应该是处理日志、事务、一致性、授权、安全、性能等。许多这种关注点被叫做横切关注点 — 往往会影响许多模块的实现。
使用目前的编程方法,跨越多个模块横切关注点会导致系统更难设计、理解、实现和迭代。
阅读完全的「我想要 AOP」系列文章:
-
第一部分
-
第二部分
-
第三部分
面向切面的编程相比之前的方法更简单的分享了关注点,从而提供横切关注点的模块化。
在本系列文章中,第一篇涉及 AOP 的概念,我首先解释了在一般复杂的软件系统中由横切关注点引起的问题。然后,我引入了 AOP 核心概念,并展示了 AOP 是如何通过横切关注点解决问题的。
这个系列的第二篇文章将介绍 AspectJ,Xerox PARC 基于 Java 实现的 AOP 框架。最后一篇文章将以几个示例的方式向你展示 AOP 的概念,并基于建立更易懂、易实现、易迭代的软件系统。
¶软件编程方法的演进
早些年的计算机科学领域,开发者直接使用机器码进行编程。不幸的是,程序员花了更多时间去考虑特定机器的指令集而不是手头的问题。慢慢地,我们迁移到高级编程语言,高级编程语言允许对底层机器码进行一些抽象。然后结构化的语言出现了;我们现在可以根据任务的执行过程来分解我们的问题。然而,随着复杂度的增长,我们需要更好的技术。面向对象的编程让我们可以把系统看成一系列的合作对象。类可以让我们隐藏接口背后的实现细节。多态提供了通用行的为和接口,并允许更特殊的组件更改指定定行为,而无需接触基本概念的实现。
编程方法和语言定义了我们与机器交流的方式。每一种新方法都提供某种分解问题的方式:机器码、独立于机器的代码、过程、类等等。每种方法都在建立某种系统需求与程序结构之间的对应关系。这些编程方法的演进让我们可以创建越来越复杂的系统。反过来复杂的系统使得我们又必须使用更先进的技术去解决这些复杂度。
目前来讲,放多新的软件项目开发都使用面向对象的编程模式。的确,面向对象的编程模式能模拟常见行为方面表现出了强大的能力。然而,我们很快将会看见,或许你已经有所体验了,面向对象的编程模式没能充分地解决许多跨区的行为的问题 — 那种通常不相关的模块。相比而言,面向切面的编程方法填补了这个空白。AOP 很可能代表了编程方法演进的下一个重要方向。
¶将系统看做一系列的关注点
我们可以将复杂系统看做是多个关注点的联合实现。典型的系统可能包含多种关注点,包括业务逻辑、性能、数据持久化 、日志,以及调试、授权、安全、线程安全 、错误检查等等。而且你还会遇到开发流程中的关注点,比如说:可理解、可维护,可追溯、更易迭代。图1描绘出了一个系统中不同模块关注点的实现。
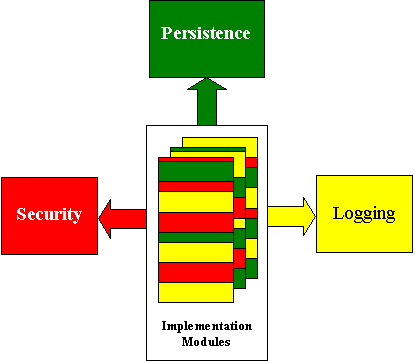 图1
图1
图2展示了一系列的需求(一个光束)通过关注点识别器(棱镜)分离各种关注点成为独立模块。这个过程就对应着我们开发过程的关注点。
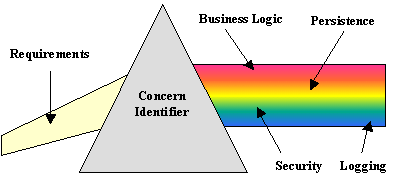 图2
图2
¶在系统中进行横切
开发者建立一个系统并且负责实现多个需求。我们可以把这些需求大体上从核心模块级别需求与系统级别需求两个维度进行分类。许多系统级别的需求相互之间(或与模块级别的需求)是正交的(相互依赖)。系统级别的需求倾向于横切许多核心模块,比如,一个个典型的企业应用包含的横切关注点有:身份验证,日志记录,资源池,管理,性能和存储管理。每个都被横切成多个子系统。比如,存储管理会影响每个业务对象。
让我们举个简单的例子,比如有一个单例实现封装了一些业务逻辑:
public class SomeBusinessClass extends OtherBusinessClass {
// 核心数据成员
// 其它数据成员:比如日志,数据一致性标识
// 重写基类中的方法
public void performSomeOperation(OperationInformation info) {
// 保证授权正常
// 保证条件正常满足
// 锁定对象保证数据一致性
// 线程进入threads access it
// 保证缓存正常
// 打印操作启动日志
// ==== 进行具体的操作 ====
// 打印操作完成日志
// 解锁对象
}
// 与上面类似的其它操作
public void save(PersitanceStorage ps) {
}
public void load(PersitanceStorage ps) {
}
}
上面的代码中我们必须考虑至少三个问题,首先,其它数据成员不属于这个类所关心的内容。其次,performSomeOperation 的实现似乎比核心操作执行了更多的逻辑;它处理了日志、授权、线程安全以及其它外部关注点。重要的是,似乎这些许多外围关注点其它类也会用到。最后,save() 和 load() 方法操作存储层,这两个方法放在这个类中比较合适还是放在其它类中比较合适,这个问题并不是很清楚。
¶横切关注的问题
虽然会跨模块横切关注点,但是现在的技术实现倾向于使用一维的方式实现,把问题聚焦在需求与实现的单一维度。这个单一维度的实现将变成核心模块级别的实现。其余的需求围绕着这个主导维度被分类。换句话说,需求空间是多维的,然而实现空间是单维的。这种不匹配会导致需求与实现之间的映射难以做到。
¶症状
使用目前的方法实现横切关注点会出现一些问题/症状,大体上分两类:
-
代码纠缠:系统中的模块可能会同时地与多个需求交互。比如,开发者经常同时考虑业务逻辑、性能、同步、日志和安全等问题。大量的并行需求导致需要许多关注点的实现同时存在,最终导致代码纠缠。
-
代码分散:由于横切关注点,按定义,很多模块都需要分离,甚至是相关的实现都需要分离。比如,一个使用数据库的系统,性能问题可能会影响所有访问数据库的模块
¶暗示
代码纠缠与代码分散对软件设计和开发有以下影响:
-
不可追溯:同时分离多个关注点会掩盖关注点与实现之间的对应关系,导致关系不清楚
-
低效的:同时实现多个关注点会打乱开发者的注意力,将注意力分散到外围问题上,这将导致低效
-
代码复用性低:由于模块实现了多个需求,其它系统将无法很容易地复用这个模块,进一步导致低效
-
代码质量低:代码纠缠会产生一些不易查觉的问题。此外,一次关注太多问题,某些关注点可能没有被真正关注到
-
难于迭代:有限的视界和受限的资源通常会产生仅解决当前关注点的设计。解决未来问题通常需要重新实现。由于这个实现并不是模块化的,这表示触摸许多模块。为了实现新需求需要修改每个子系统可能会引起不一致的问题。它还需要大量的测试工作来保证实现做出的变更没有引入新问题。
¶目前的解决方式
由于大多数系统都可以横切关注点,因此出现模块化实现的一些技术就不足为奇了。这些技术包括混入(mix-in)类,设计模式和领域特定的解决方案。
使用混入类可以让你延迟分离关注点到最终的实现。主类包含混入类实例,并允许系统的其他部分设置该实例。例如,上面的信用卡处理例子,将一个实现了业务逻辑的类组合成混入类,系统的其它模块可以通过配置来获取适合自身的日志器。例如,日志器可以设置成使用文件系统或者消息中间件。发送日志的被延后了,但是各个消息发送点(调用的地方)还是需要加入相关的代码。
基于行为的设计模式,比如说访问者、模板方法,可以让你延迟实现。但是就像混入类一样,控制操作—调用访问逻辑或者模板方法—仍然在主类中。
领域特定的解决方案,比如说框架和应用服务,让开发者可以用模块化的方式实现横切关注点。比如 EJB 架构,在安全、管理、性能和持久容器管理方面实现横切关注点。Bean 的开发者专注于业务逻辑,部署工程师专注于部署相关问题,比如 bean-data 与数据库的对应关系。对于 Bean 开发者来讲其余需要关注的就只有存储的问题了。在这个例子中你可以使用基于 XML 的映射描述符来实现横切关注点。
领域特定的解决方案提供了一种特殊的办法来解决指定的问题。它的缺点是,开发者必须为它学习新的技术。然后由于这些解决方案都是领域特定的,它并不能直接有效地横切关注点。
¶构架设计的窘境
好的系统架构会考眼前与未来的一些需求,从而避免打补丁式的实现。但是这有一个问题,预测未来是一件非常困难的事情。如果你没有搞清楚未来的需求,那就需要改变、或者将系统的很多地方重新实现。另外一方面,将精力聚焦在低可能性的一些需求会导致过度的设计、混乱和臃肿的系统。因此系统构架的一个困境是:应该设计到什么程度?我应该保守式的设计还是盈余式的设计。
比方说,构架中是否应该追念一个初始化时并不需要的日志系统?如果是,日志打点的地方应该在哪里,什么样的信息应该被记录?这个是一个类似的出现在优化相关需求过程中的困境—我们很少提前知道瓶颈,常归的做法是构建一个系统,对其进行分析,并通过优化进行改进以提高性能。这种方法会潜在引导我们根据分析结果去修改系统很多部分。过不了多久,一个新的瓶颈又会出现,而这个瓶颈很可能就是上一步的改进引起的。设计可复用库架构的任务会变得非常困难,因为找到库的所有的使用场景并非易事。
总之,架构师很少知道系统所有可能需要解决的问题。即使提前了解了需求,一个实现的具体细节可能并没有被考虑到。因此,架构师面临着究竟应该保守设计还是盈余设计的困境。
¶AOP 的基本概念
到这里我们主要讨论了模块化的横切关注点会有很大益处。研究人员已经研究了在「关注点分离」这一更为泛化的主题下完成该任务的各种方法。 AOP 就是这样的一种方法。AOP 力争将关注点彻底分离,以克服上述问题。
AOP 的核心在于,以松散耦合的方式让你实现一个独立的关注点,然后结合这些实现成为一个最终的系统。确实,AOP 使用松散耦合、模块化的分离关注点的方式来创建系统。相反,OOP,则使用松散耦合、模块化的实现共同关注点方式来创建系统。AOP 中模块化的单位叫做横切面(aspect),好比 OOP 中共同的关注点是类(class)。
AOP涉及三个不同的开发步骤:
-
切面分解:将需求分解并识别出横切关注点与共同关注点。你可以将系统级别的关注点与模块级别关注点分离。比如说,上面提到的信用卡模块,你需要识别三种关注点:信用卡核心流程,日志和授权。
-
关注点实现:分离的实现各个关注点。像上面的例子一样,你可以单独实现核心流程、日志和授权三个单元。
-
切面重组:在这个步骤中,切面集成器通过创建模块化单元来指定重组规则 — 切面。重组过程(也称为编织或集成)使用此信息来组合成最终系统。比如上面的信用卡例子,你得使用一种 AOP 实现的语言具体/规范化操作中哪一步需要打日志。还得指定每个操作在被前都需要清除授权。
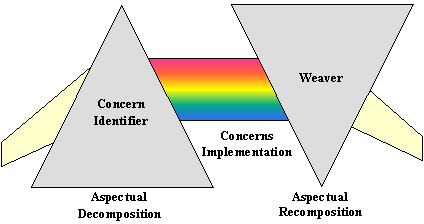
AOP 实现横切关注点的方法与 OOP 不一样。对于 AOP 来讲,每个关注点的实现并不会意识到其它关注点下在横切它。比如上面的信用卡例子,信用止处理模块并不知道其它的关注点是日志、授权操作。这对于 OOP 来讲意味着很大的范式转换。
注意:一个 AOP 的实现可以采用其它编程方法作为它的基本方法。因此可以保证基础系统非常完善。比如说,一个 AOP 的实现可以选择 OOP 做为基础系统,这样就可以获得 OOP 共同关注点的优势。每个独立的关注点可以采用 OOP 技术识别关注点。这类似于过程式的语言可以做为许多 OOP 语言的基础语言。
¶编织的例子
编织器是一个将独立的关注点纺织起来的过程。换句话说,编织器根据提供给它的某些标准将不同的执行逻辑片段编织起来。
为了能够演示编织过程,让我们回到之前的信用卡处理系统的例子。为了看起来更简单,我们只考虑两个操作:信用卡和借记卡。并且已经有一个合适的日志器了。
考虑下面的信用卡处理模块:
public class CreditCardProcessor {
public void debit(CreditCard card, Currency amount)
throws InvalidCardException, NotEnoughAmountException,
CardExpiredException {
// Debiting logic
}
public void credit(CreditCard card, Currency amount)
throws InvalidCardException {
// Crediting logic
}
}
同样还有一个日志接口:
public interface Logger {
public void log(String message);
}
我们想要的组合需要以下编织规则,这些规则以自然语言表示(稍后将提供这些编织规则的编程语言版本):
-
打印每个公共操作的开始
-
打印每个公共操作完成
-
打印每个公共操作的异常
编织器随后将使用这些规则,并关注每个实现以产生等价于以下代码的效果。
public class CreditCardProcessorWithLogging {
Logger _logger;
public void debit(CreditCard card, Money amount)
throws InvalidCardException, NotEnoughAmountException,
CardExpiredException {
_logger.log("Starting CreditCardProcessor.credit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
// Debiting logic
_logger.log("Completing CreditCardProcessor.credit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
}
public void credit(CreditCard card, Money amount)
throws InvalidCardException {
System.out.println("Debiting");
_logger.log("Starting CreditCardProcessor.debit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
// Crediting logic
_logger.log("Completing CreditCardProcessor.credit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
}
}
¶分解 AOP 语言
就像其它编程语言方法的实现,AOP 实现包括两个部分:一种语言规范和一种实现。语言规范描述语言的构成与语法。实现则根据语言规范去论证代码的正确性,然后转换成机器码然后执行。在这小节中,我将解释 AOP 语言的不同组成部分。
¶AOP 语言的规范
在一个高层次上,AOP 语言有两种组件:
-
关注点的实现:创建一个独立的需求与代码之间的对应关系,这样编译器才能翻译成可执行代码。由于关注点的实现需要通过具体的过程,你可以使用传统的语言,比如 C,C++ 或者 Java
-
编织规则的规范:如何将独立的关注点实现结合成最终的系统。为了达到这个目标,实现需要使用或者创建一种语言来具体说明结合的规则。具体化编织规则的语言可以是实现语言的一种扩展,或者其它完全不同的东西。
¶AOP 语言的实现
AOP 语言编译器有以下两个逻辑步骤:
-
结合独立的关注点
-
转换最终结果成可执行代码
AOP 语言实现编织器的方法有很多,包括源码到源码的翻译。你可以预处理独立切面的源码,然后将它加工成编织过的源码。然后 AOP 编译器将这些源码转交给基本语言编译器用来生成最终可执行代码,最后让 Java 编译器把代码编译成子节码。同样的,编织过程可以是子节码级别的;毕竟,子节码也是一种源代码。引外底层系统—VM虚拟机,是可以感知到切面的。使用这种基于 Java 的 AOP 实现,比如,VM虚拟机将首先加载编织规则,然后将这些规则应用到随后加载的类中。换句话说,它表现得像是 JIT 化的切面编织。
¶AOP 的益处
AOP 有助于克服由代码纠缠和代码分散引起的上述问题。以下是 AOP 提供的其他优势:
-
模块化地横切关注点:AOP 使得每个独立的关注点有最小化的耦合,最终产出模块化的实现。这样的一种实现会产生很少的重复代码。由于每个关注点的实现是分离的,也将减少无用代码,更重要的模块化的实现让最终系统更易于理解与维护。
-
更便于系统迭代:由于切面模块对于横切关注点是无感知的,添加新功能、新切面将变得简单。而且当你在系统中添加新模块时,现有的切面将横切它们,这有助于你构建一系列连贯的迭代演进。
-
延迟设计目标的绑定:回顾下架构师的困境,有了 AOP,架构师对于将来的需求就可以推迟做出设计上的决定,因为他可以用分离的切面来实现。
-
更高的代码复用性:由于 AOP 分离的实现每个切面,每个独立模块之间的耦合更加的松散。比如说,你可以使用不同的日志器来记录你模块与数据库的操作。通常来讲,松散耦合的实现是代码高复用性的关键点。 AOP 的实现比 OOP 的实现更加松散耦合。
¶AspectJ:一种 Java 的 AOP 实现
略